
La mayoría del entrenamiento de los modelos de inteligencia artificial (IA) se lleva a cabo en una ubicación central. Usualmente, esta depende de conjuntos de datos fusionados y centralizados. Ahora bien, este enfoque puede ser ineficiente y costoso, pues grandes volúmenes de datos se tienen que trasladar a la misma fuente. Una alternativa es el aprendizaje distribuido, el cual funciona particularmente bien para la computación en el borde.
Dentro de este campo, Hewlett Packard anunció el lanzamiento de HPE Swarm Learning. Se trata de la primera solución de aprendizaje automático descentralizada, con preservación de privacidad para el borde o los sitios distribuidos. Destaca su capacidad de compartir y unificar el aprendizaje automático sin comprometer la privacidad de los datos. Entre muchas otras, tiene aplicaciones en el diagnóstico de enfermedades.
A diferencia de otras soluciones en el mercado, HPE Swarm Learning no depende de un servidor central. La herramienta proporciona contenedores que se integran fácilmente en los modelos de inteligencia artificial a través de su API. Con ella, los usuarios pueden compartir los aprendizajes de su modelo de IA para mejorar el entrenamiento sin revelar datos reales.
«El aprendizaje distribuido es un nuevo y potente enfoque en torno a la IA que ha progresado para resolver desafíos globales, tales como mejorar la atención médica», dijo Justin Hotard, vicepresidente ejecutivo y director general de HPC e IA en HPE.
Ciberseguridad con blockchain
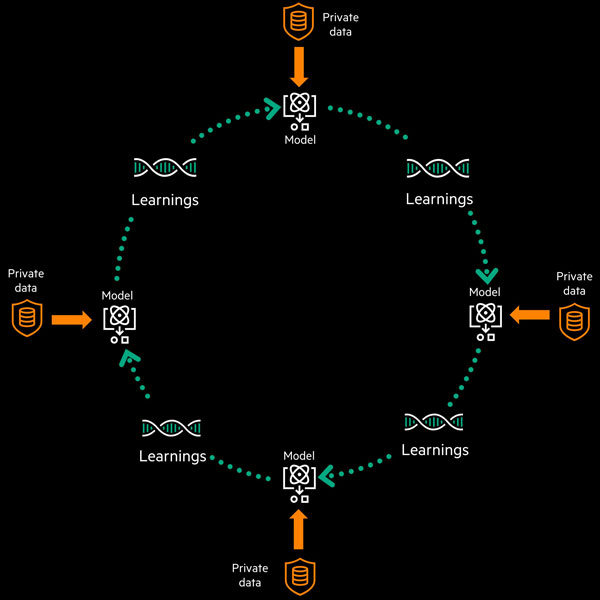
El enfoque de aprendizaje distribuido aprovecha de manera segura la computación en el borde. De esta manera, las empresas pueden tomar decisiones más rápido, en el punto de impacto, lo que genera mejores experiencias y resultados. Asimismo, al compartir los aprendizajes entre una organización y otra en la fuente de datos, varias industrias del mundo pueden unificar y mejorar aún más la inteligencia que puede conducir a resultados empresariales y sociales impresionantes.
Sin embargo, compartir los datos externamente puede representar un desafío. Afecta principalmente a las organizaciones que deben cumplir con requerimientos de gobernabilidad de datos, regulativos o que exigen que permanezcan en su ubicación.
Para asegurar que sólo los aprendizajes captados desde el borde se compartan, y no los datos en sí, HPE Swarm Learning utiliza tecnología blockchain. Así incorpora a los miembros de manera segura. También se pueden elegir líderes de forma dinámica y fusionar los parámetros del modelo para brindar resiliencia y seguridad a la red masiva.
Además, debido a que únicamente comparte los aprendizajes, permite a los usuarios aprovechar grandes conjuntos de datos de entrenamiento, sin comprometer la privacidad. Adicionalmente, ayuda a eliminar el sesgo para incrementar la precisión en los modelos.
Aprendizaje distribuido para diagnosticar cáncer

Con la solución de aprendizaje distribuido, los hospitales pueden aprovechar, por ejemplo, los expedientes de imagenología y los datos de expresión genética. Al compartir los aprendizajes de la IA con otros hospitales, es factible mejorar el diagnóstico de enfermedades. Y con la ventaja de proteger la información de los pacientes.
Uno de los primeros usuarios del aprendizaje distribuido en la atención sanitaria es el Hospital Universitario de la Universidad RWTH Aachen, en Alemania. Investigadores de histopatología consiguieron acelerar el diagnóstico de cáncer de colon. Para ello, utilizaron la solución de aprendizaje distribuido para el procesamiento de imágenes y predecir alteraciones genéticas que derivan en células cancerosas.
Los investigadores entrenaron los modelos de IA con HPE Swarm Learning en tres grupos de pacientes de Irlanda, Alemania y Estados Unidos. Confirmaron el rendimiento predictivo en dos conjuntos de datos independientes del Reino Unido, utilizando los mismos modelos de IA basados en aprendizaje masivo.
Los resultados demostraron que los modelos de IA originales, entrenados únicamente con datos locales, se superaron utilizando el aprendizaje distribuido. También se confirmó que no fue necesario compartir los datos de los pacientes con otras entidades para mejorar las predicciones.









